Deep Learning for tabular data augmentation



When it comes to DeepLearning, the more data we have the better the chances are to get a great performing model. In fields like image recognition research has already came up with quite a few clever ideas how to use the existing data to create more data out of it. This is called data augmentation.
However, when we look at Deep Learning in the tabular data context, there are still many concepts missing. What I would like to show in this blogpost is a way to augment tabular data, what we could use in order to train a DeepLearning Model on more tabular data, or which can be used to create data of underrepresented classes.
I want to show graphically how this newly created data is sampled from the distribution of the underlying data and hence how this data can help to make better Deep Learning models.
I've already created a small library, which I called deep_tabular_augmentation. In here I've created a class, which handles all of the tabular data augmentation.
import pandas as pd
import numpy as np
import torch
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import deep_tabular_augmentation as dta
import warnings; warnings.simplefilter('ignore')
So first, we need to get some data. Here, I've got some data on the infamous wine-dataset.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
DATA_PATH = 'data/wine.csv'
df = pd.read_csv(DATA_PATH, sep=',')
df.head()
cols = df.columns
We then build a DataLoader, in which we also standardize our data. We save the scaler in our dataset to make use of it later, when we invert the scaling.
def load_and_standardize_data(path):
# read in from csv
df = pd.read_csv(path, sep=',')
# replace nan with -99
df = df.fillna(-99)
df = df.values.reshape(-1, df.shape[1]).astype('float32')
# randomly split
X_train, X_test = train_test_split(df, test_size=0.3, random_state=42)
# standardize values
scaler = preprocessing.StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
return X_train, X_test, scaler
from torch.utils.data import Dataset, DataLoader
class DataBuilder(Dataset):
def __init__(self, path, train=True):
self.X_train, self.X_test, self.standardizer = load_and_standardize_data(DATA_PATH)
if train:
self.x = torch.from_numpy(self.X_train)
self.len=self.x.shape[0]
else:
self.x = torch.from_numpy(self.X_test)
self.len=self.x.shape[0]
del self.X_train
del self.X_test
def __getitem__(self,index):
return self.x[index]
def __len__(self):
return self.len
traindata_set=DataBuilder(DATA_PATH, train=True)
testdata_set=DataBuilder(DATA_PATH, train=False)
trainloader=DataLoader(dataset=traindata_set,batch_size=1024)
testloader=DataLoader(dataset=testdata_set,batch_size=1024)
trainloader.dataset.x.shape, testloader.dataset.x.shape
We've build our train and test datasets, and with the help of DataLoaders we also turned them into tensors. So, let's use deep_tabular_augmentation now. The class needs seven inputs: trainloader, testloader, device on which to run the traning, the input dimension (in this case: 14), and how many nodes the first and second hidden layers should have. Finally, we can also specify the number of latent factors. These latent factors will contain all the condensed information, meaning that we can use these latent factors to recreate the original 14 input dimensions (e.g. our data).
D_in = traindata_set.x.shape[1]
H = 50
H2 = 12
autoenc_model = dta.AutoencoderModel(trainloader, testloader, device, D_in, H, H2, latent_dim=3)
After we've successfully initiated our model, let's train it and call the trained model "autoenc_model_fit".
autoenc_model_fit = autoenc_model.fit(epochs=600)
Now, all we need is to create some fake data based on the trained model. How this works is the following: we know the learned parameters for the mean and the variance of our latent factors. Then, we use a normal distribution with the mean and variance of each of the latent factors to sample a value for latent factor 1,2 and 3 (because we've got three latent facots in this case). These generated starting points for our latent factors are then used to inflate towards the 14 real input variables. Let's see how it's done:
scaler = trainloader.dataset.standardizer
pred = autoenc_model_fit.predict_df(no_samples=500, cols=cols, scaler=scaler)
df_fake['Wine'] = np.round(df_fake['Wine']).astype(int)
df_fake['Wine'] = np.where(df_fake['Wine']<1, 1, df_fake['Wine'])
df_fake['Wine'] = np.where(df_fake['Wine']>3, 3, df_fake['Wine'])
df_fake.head()
The deep_tabular_augmentation library has another method in its sleeve: predict_with_noise. What this does is the following, sampling from a normal distribution each element (independend of each other element) will be multiplied by 1 plus the sampled number. Why should we do this? The answer is that the Variational Autoencoder works similar to a PCA, resulting in sharper defined relations between variables. So the Variational Autoencoder keeps mean and standard deviance within the variables, however, the trained parameters of the model already find out "hidden" relations between variables. When these relations are linear the Variational Autoencoder de facto performs a PCA. We'll have a look at it in a second.
df_fake_with_noise = autoenc_model_fit.predict_with_noise_df(no_samples=500, scaler=scaler, cols=cols, mu=0, sigma=0.05, group_var='Wine')
df_fake_with_noise['Wine'] = np.round(df_fake_with_noise['Wine']).astype(int)
df_fake_with_noise['Wine'] = np.where(df_fake_with_noise['Wine']<1, 1, df_fake_with_noise['Wine'])
df_fake_with_noise['Wine'] = np.where(df_fake_with_noise['Wine']>3, 3, df_fake_with_noise['Wine'])
df_fake_with_noise.head()
Let's have a look at the descriptives, especially the mean. Can you spot a difference between the real and the fake data?
df.groupby('Wine').describe().loc[:,(slice(None),['mean'])]
df_fake.groupby('Wine').describe().loc[:,(slice(None),['mean'])]
df_fake_with_noise.groupby('Wine').describe().loc[:,(slice(None),['mean'])]
Now let's have a graphical look on how the fake data looks vs the real data.
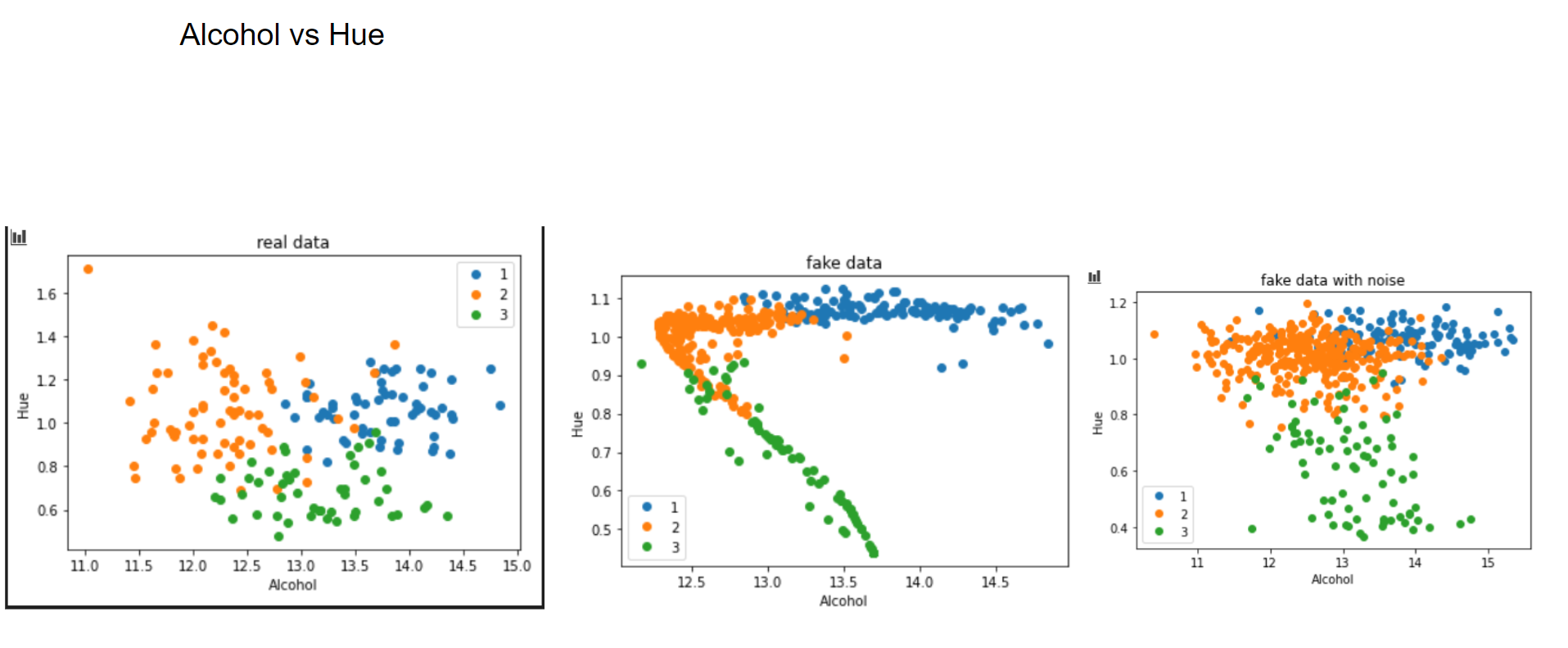
This is what I meant by "performing a PCA". One can clearly see how the Variational Autoencoder gave structure to the relation of Alcohol and Hue. If we add noise to it, this relation vanishes. But what happens, if we use more than 3 latent factors? This is the result with 14 (=input variables) latent factors:
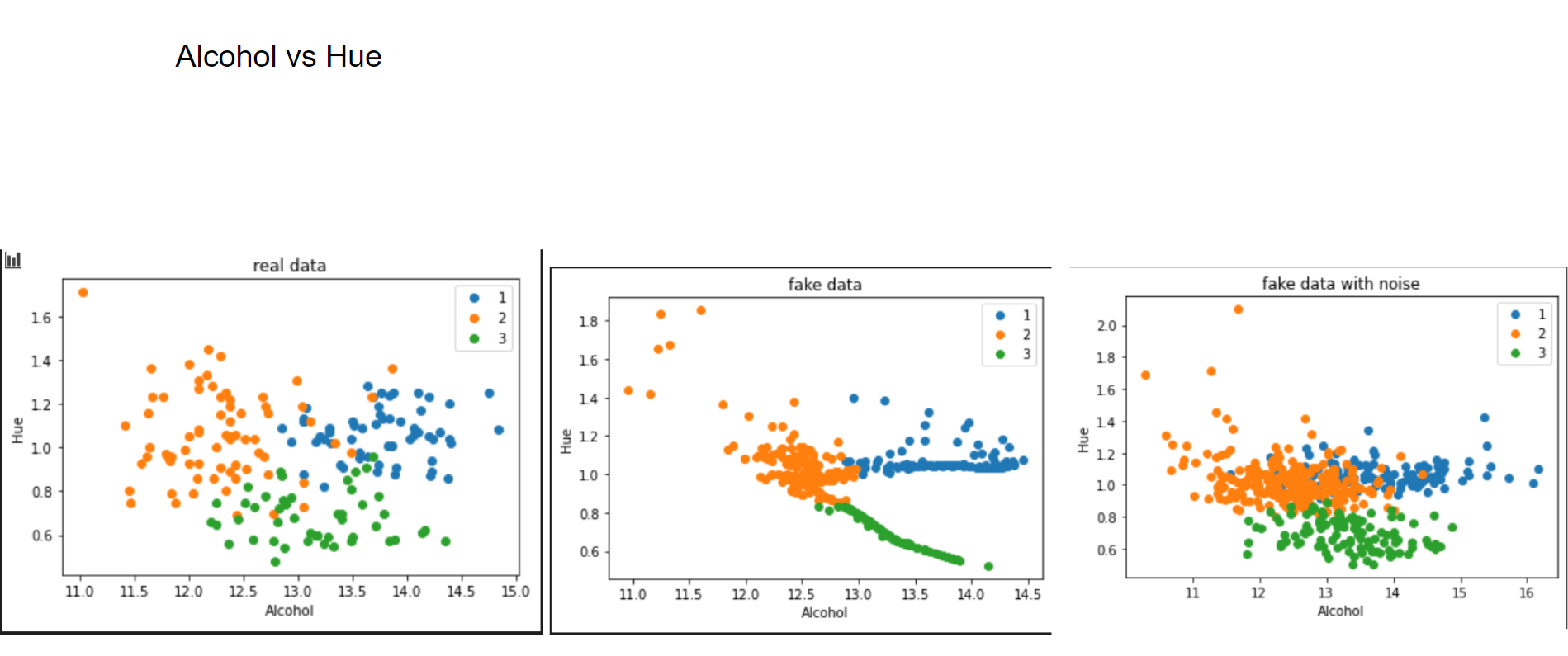
The same pattern emerges. However, when applying random noise to it, the resulting data looks pretty much like the real data.
Now let's have a look at some distributions. The first image always represents the results with 3 latent factors, the second one with 14 latent factors.
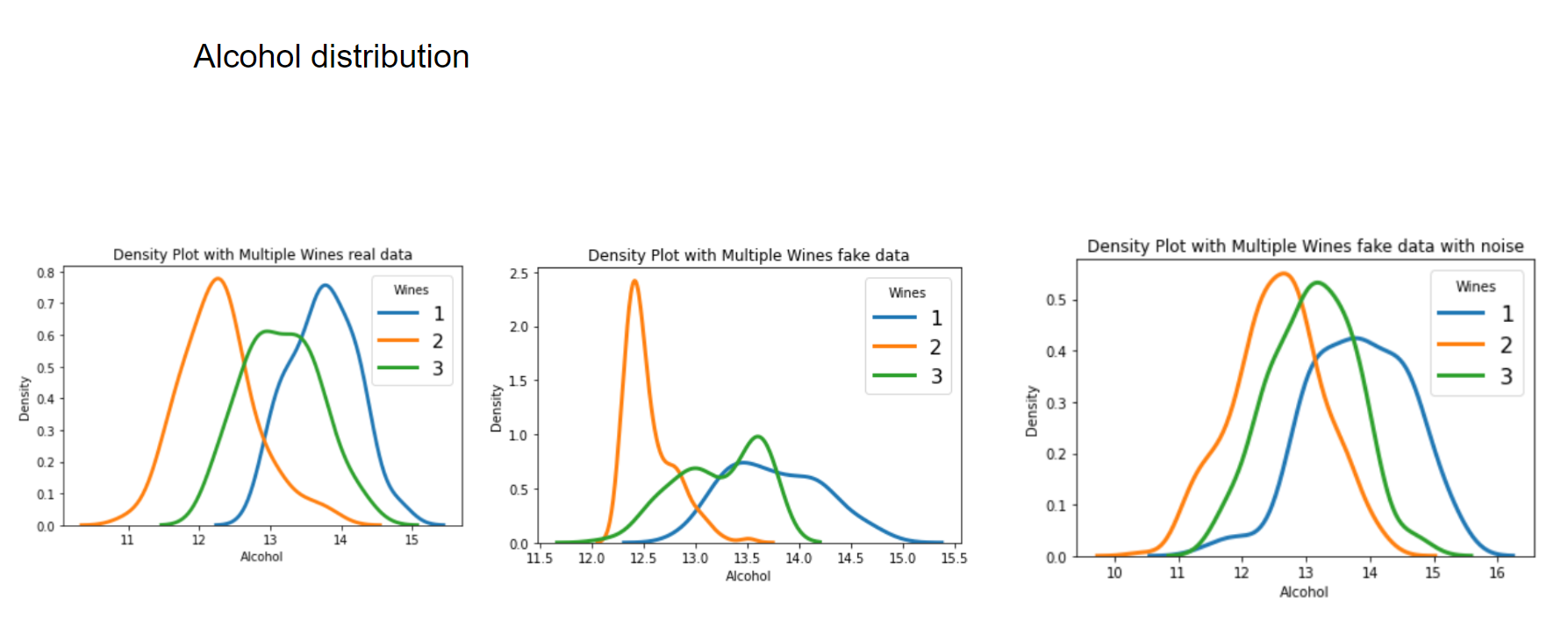
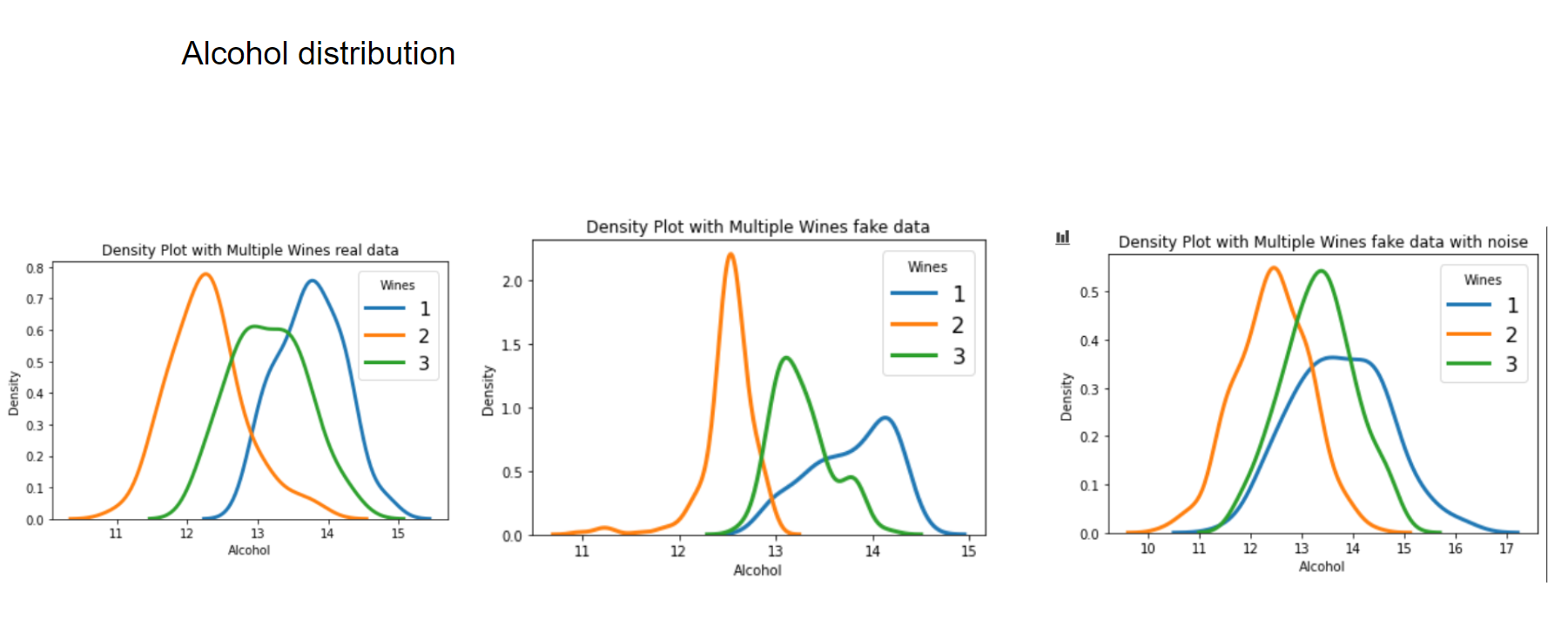
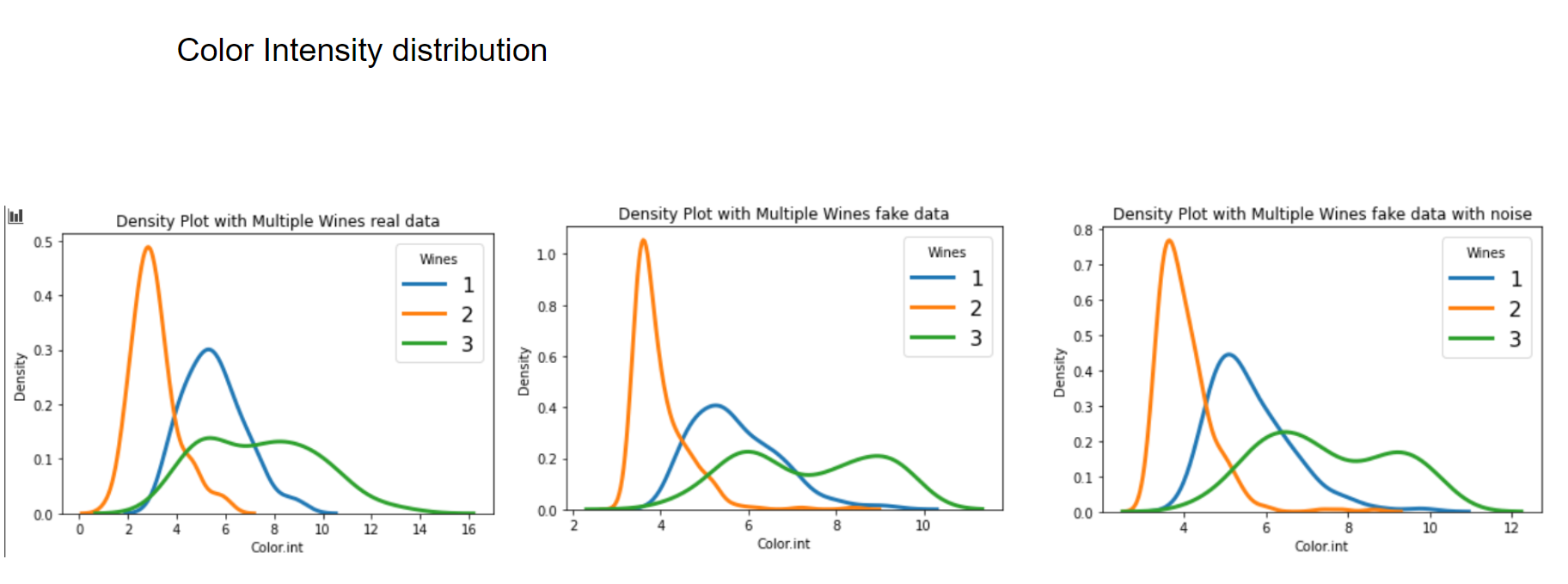
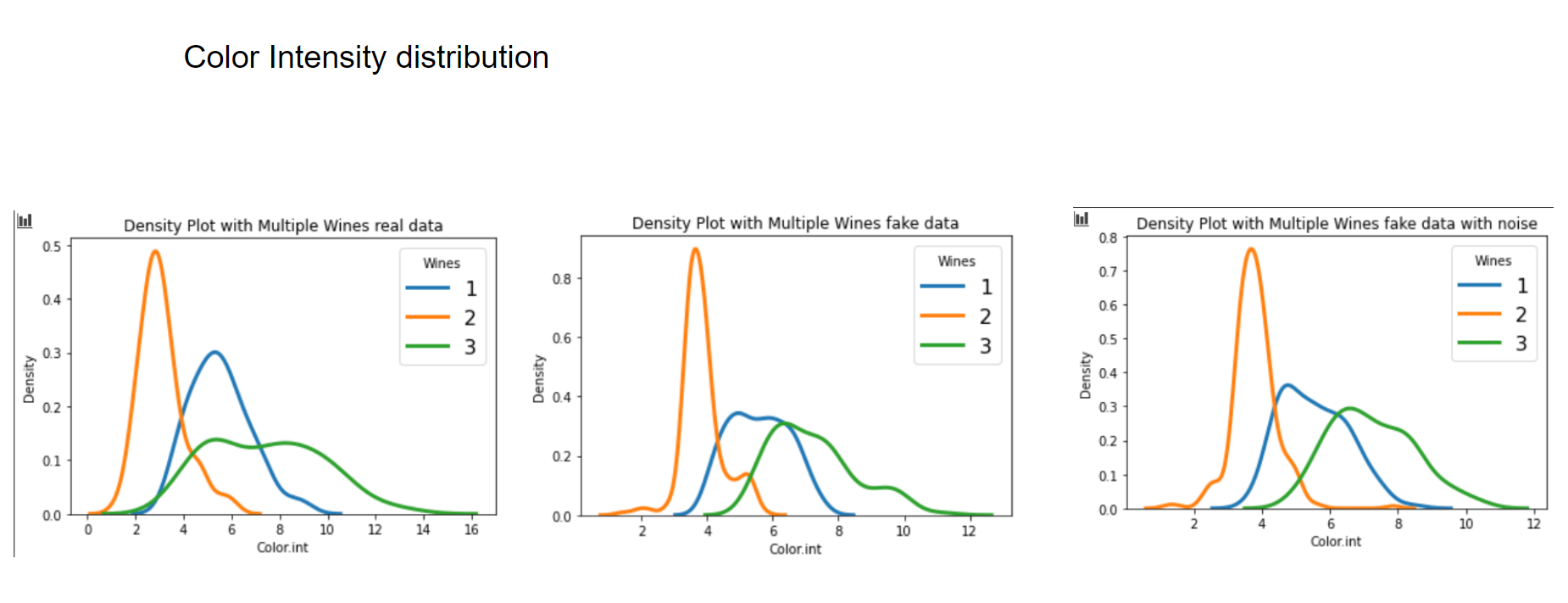
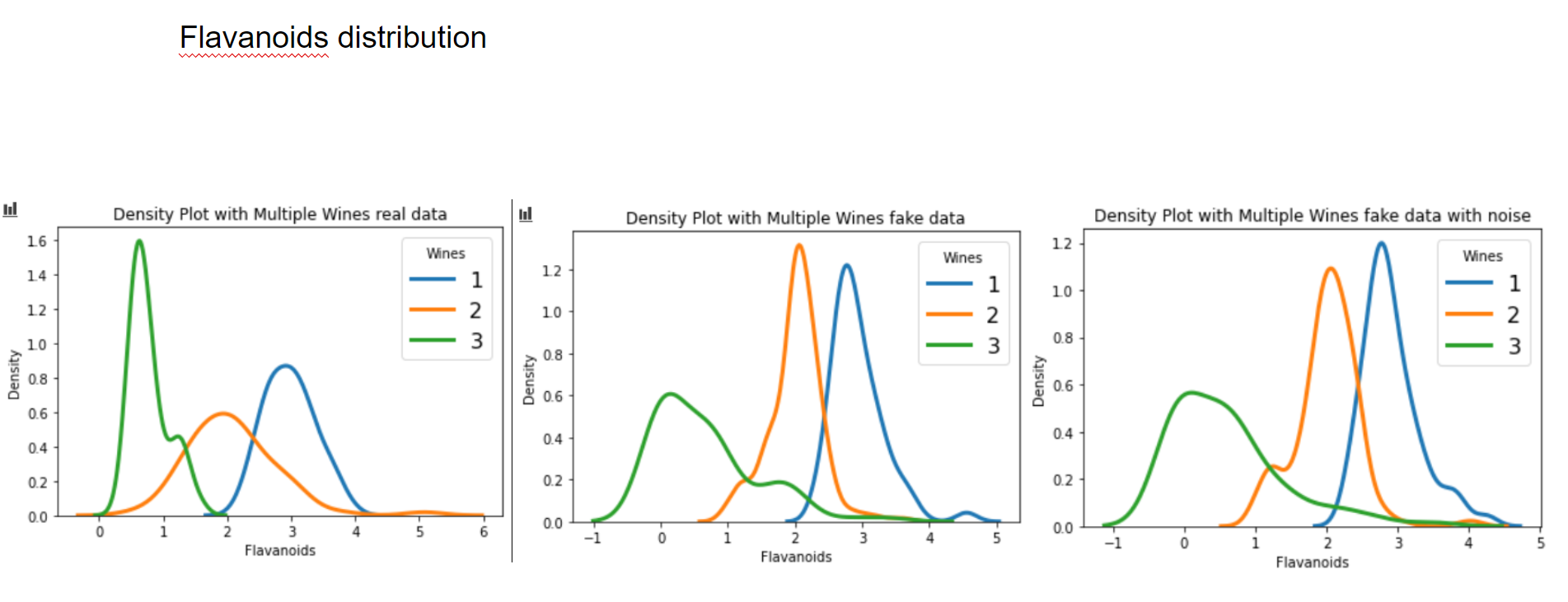
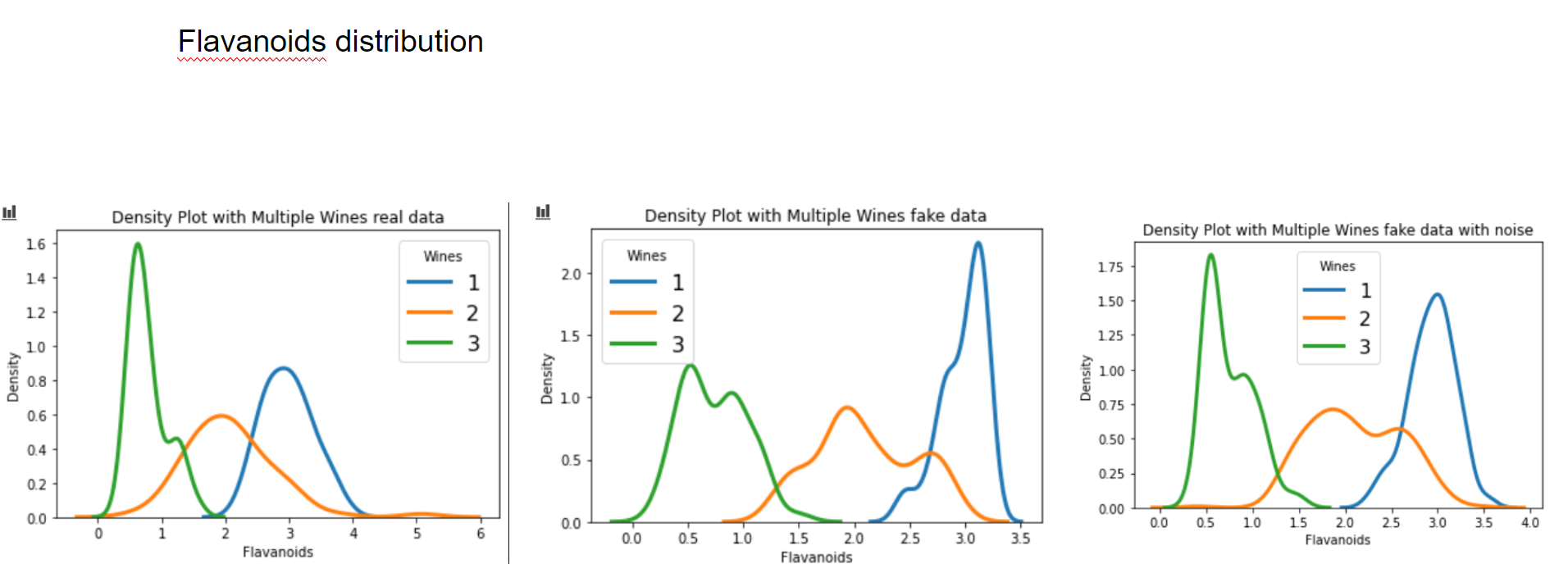
We see that when using a Variational Autoencoder to make data augmentation on tabular data, it actually already finds relations between variables. If we want to get rid of this effect and add random noise to the data, the resulting distributions look pretty much like the original, real data points. How can we use these insights to improve machine learning/deep learning models? This I will cover in an upcoming blogpost.
Until then, stay tuned for more! Lasse